
title= 游戏声音设计学习
地狱之刃2:塞娜的传说
Hybrid breathing混合呼吸设计
在自由度高的地方,采用非线性的程序设计呼吸(设置state等进行切换);
在线性化的叙事流程中(例如实时渲染的动画),采用线性的录制的呼吸声,在演员录制动捕的时候进行同期录音。
通过在SEQUENCE中添加marker点,marker触发后,会播放线性的声音,播放结束后会进入程序性的声音,直到触发下一个marker。
可以通过RTPC来控制线性流程中,不同阶段的声音变化。
RMS Reading
通过监测Ambience 的RMS值,来控制dialogue的值,然后再反过来控制对话对ambience 的duck值。
为了带来更深、震撼的情感体验,将语音和音乐推到最前面是个可选项。
Trition Acoustics
Project Acoustics基于Triton技术,这是一个先进的声学模拟引擎,能够处理复杂的三维空间中的声音传播和反射。
支持Untiy\Unreal以及wwise.
汽车引擎声音设计
https://www.audiokinetic.com/zh/blog/loop-based-car-engine-design-with-wwise-part-1/
漫威蜘蛛侠2
Mixing
总线设计
非必要情况下,不会添加新的总线,会让整体局面更复杂。
以减法为主,极少做加法
创建总线的一些情境:
- state\RTPC。控制一组声音的音量或者其他参数
- 动态EQ\混音。有时候为了针对不同的频段做动态均衡。
- 压缩\效果
- 发声数限制。为了去限制一个组别的发声数量。
- 电平检测。为了对一些内容进行检测。
- 总线配置差异化。某一组的音频需要做特殊的效果。
- 是否暂停。是否需要暂停某些音频。
- 不用于静态音量差异。总线上的音量尽可能保持默认。
电平检测
检测的电平值本身的意义不是特别大,主要是利用meter值去进行其他操作。
例如对白,会分别检测总的,以及低中高三个频段的电平值。
动态均衡
通过电平检测值实现。
主要应用场景:
- 对白 优先于 音乐
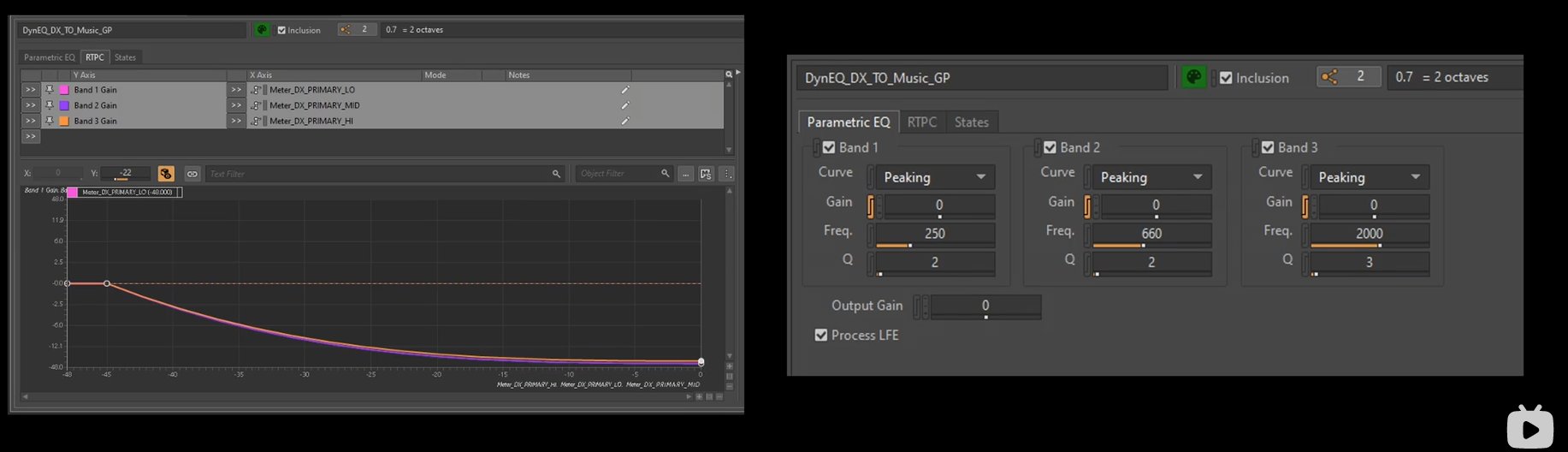 ![image-20250215162814960]
![image-20250215162814960] - 对白 优先于 音效
- 战斗音效和关键音效 优先于 环境音效和非关键音效
- 战斗音效和关键音效 优先于 音乐
- 音乐 优先于 环境音
- 音乐 优先于 非关键音效
特殊的侧链压缩处理增强打击感
通过减法增强效果。
通过战斗音效的电平检测,来降低对应混响的音量,以达到增强打击感的效果。
城市声景
城市声音景观组成:
第一部分(可见的):环境点声源、行人、载具、其他变量(天气或者犯罪事件)
第二部分(不见的):环境音基调,远距离区域声音,海岸线\水面声音
环境音
每个不同的区域有独特的环境音基调;
需要大体积声源;
内容随高度进行声响摆位。(在高处时,声音大部分在下面,通过RTPC控制。
)
远距离区域系统
中远距离环境音,中远两个距离分别有5个发声点环绕着玩家,与玩家保持固定的偏移,只检测了水平的距离。(无论你高度如何,中远距离环境音不会改变)
具体的声音内容通过State和RTPC进行调整。例如,水上的监测点则不会发出声音。
DDS屏蔽值(shelter value)
点声源与听者的屏蔽程度,从听者向DDS点声源进行射线检测,仅作用于水平面。
邻近区域
海岸线周边样条曲线,在曲线上播放海水拍打音效
性能优化
- 转码设置
ATRAC9解码:索尼的PS解码器,压缩比很不错,但是文件体积很大
硬件解码:所有声音
软件解码\CPU:Wwise内容
WEM Opus解码:压缩比更大,且文件质量也有保证,但会超出硬件解码预算,导致部分音频不会被播放。
硬件解码:所有声音
软件解码\CPU:Wwise内容
Vobis解码:只用vorbis超出CPU预算。
硬件解码:无
软件解码\CPU:Wwise内容、所有声音
最终采用组合解码的方式,改善了内存与磁盘的使用空间,音频保真度没有妥协,根据声音类型进行解码方式选择sharesets:
Ambience_Beds
Ambience_Default
Ambience_Rain
CHR_Default
Cine_Atmos
Cine_Default
Cine_Dialogue
CS_Default
Default
Dialog Default
Dialog Screen Reader
Foley_Cloth_Footsteps
Foley_Water
Hero_Abilities
LFE_Discrete
Haptics_Default
Music_Default
NPC_Weapons&Attack
Objects_General
Objects_Physics
UI_HUD
Vehicles
Vehicles Engines
Walla Default
Weapons
Weapons_Tails
ATRAC9:短音效、数量少的声音 - UI、物品、打斗、技能等
WEM Opus:长文件、数量多的 - 对白音乐、环境、CG贴片等
Vorbis:可能会同时大量播放的 - 载具,雨声等
- 流播放
音频的流播放(Streaming) 是一种动态加载和播放音频资源的技术。其核心思想是:不一次性将整个音频文件加载到内存中,而是在播放过程中按需从存储设备(如硬盘、SSD)逐块读取音频数据,边读取边播放。这一技术主要用于处理大型音频文件(如背景音乐、长对话、环境音效等),以优化内存使用和性能。
流播放的工作原理
分段加载:
音频文件被分成多个小数据块(chunks),播放时仅加载当前需要播放的部分到内存缓冲区。
动态缓冲:
在播放过程中,后台持续从存储设备读取后续数据块,填充到内存缓冲区,确保播放的连续性。
内存释放:
已播放完的数据块会被及时释放,避免内存占用过高。
为什么需要流播放?
节省内存:
大型音频文件(如长达数分钟的背景音乐)直接加载到内存会占用大量空间,流播放仅保留当前播放的片段。
支持大文件:
适用于开放世界游戏、电影化叙事游戏中需要长时间播放的高质量音频。
动态内容切换:
支持无缝切换不同音频片段(如根据游戏场景动态调整环境音效)。
减少加载延迟:
无需等待整个文件加载完成即可开始播放。
流播放的典型应用场景
背景音乐(BGM):
长时播放的高保真音乐,尤其适用于开放世界或剧情驱动的游戏。
语音对话:
角色长篇对话或剧情旁白,避免一次性加载数百MB的语音文件。
环境音效:
持续的风声、雨声、城市噪音等动态环境音效。
动态音乐系统:
根据玩家行为实时混合不同音轨(如战斗音乐过渡到探索音乐)。
流播放的优缺点
优点:
显著降低内存占用。
支持超大音频文件(如数十分钟的音乐)。
灵活应对动态内容需求(如随机事件触发的音效)。
缺点:
增加磁盘I/O压力,可能影响性能(需优化读取策略)。
需要管理缓冲区,防止播放中断(如硬盘速度不足时)。
对音频格式有要求(需支持分段解码,如.wav、.ogg等流式编码格式)。
实现流播放的关键技术
音频中间件支持:
Wwise、FMOD等工具提供流播放接口,简化开发流程。
例如在FMOD中使用 FMOD_CREATESTREAM 标志创建流式音频。
引擎集成:
Unity通过 AudioClip 的 LoadType 设置为 Streaming 实现。
Unreal Engine 通过 Sound Wave 的 Streaming 选项启用。
数据预读取与缓冲:
设置合理的缓冲区大小,平衡内存占用和读取频率。
使用多线程避免主线程卡顿。
File Packager 负责将启用了流播放(Streaming)的 音频文件 打包成外部文件(如 .pck 或 .bnk),这些文件独立于 SoundBank 存在。
实际音频数据(如 .wav、.ogg 文件)。
流播放所需的块(Chunk)索引信息。
运行时功能:
游戏通过 Wwise 引擎直接从这些外部包中按需加载音频数据块,实现流播放。
SoundBank 主要存储的是 音频事件的逻辑定义 和 音频资源的元数据,例如:
事件(Events)和动作(Actions)。
音频对象的结构(如容器、随机播放规则、混合总线参数)。
非流式音频数据(如果音频未启用流播放,则音频文件会被直接打包进 SoundBank)。
对流式音频文件的引用(如果音频启用了流播放,SoundBank 仅存储其路径和元数据,而非实际音频数据)。
内存处理
减少运行内存的占用
- 从soundbank中移除未使用的音频内容
很多结构化的数据并没有被实际运用。 - 重构复杂的大型的switch容器,可以减少内存的占用
3D音频混音中的性能
EQ并不适用于音频对象
3D音频对象会大幅提升CPU的使用率
将音频对象留给某些特定的声音,例如环境声或者敌人。
3D Audio Bed Mixer plugin会节约大量内存。
总体CPU性能表现
减少API调用。
在不需要时动态bypass掉插件或者提前离线渲染好。
先提前管理好声音的数目,再进入WWise,不要过度依赖于playback objects limits。
Wwise中设置目标平台的最大发声数。例如一百个。
好好利用Wwise的profiler,来进行性能分析。
永劫无间手游移植
移动端移植
Wwise内优化方案
- 手机端采样率是36K以及24K。
- 过长的音频文件采样streaming加载。需要结合限制同时播放音频数量以及设置加载优先级,以防止手机的I/O性能过载。
- 资源合并删减,简化structure。、
- Bank拆分。(将3p的资源进行了删减和优化)
内存优化
- 用量与I\O:用量过低会导致IO更为频繁,因此需要平衡
- Soundbank:进行评估,是否继续引用或者进行卸载
- 动静态分离:UI、脚步声等需要常驻的Bank,即使处于离线也不会被卸载
- LRU:根据内存情况,动态的可以卸载掉被评估的,不被需要(不重要)的bank
- 内存分配器:在RPmalloc上做分级机制,对老的手机进行更多优化等操作
性能优化
- 复用对象池,减少不必要的重建
- Tick rate策略:对object的更新是基于优先级,例如距离或者重要度等,有的是每帧更新,有的可能5帧才更新一次。
- sample rate:采样率下采。部分机型对音频质量要求高,当发现你采样率下调之后,会自己上采样,增加功耗。
- 梯度计算:评估某个声音是否需要继续计算,如果不需要则直接打回。某些游戏会继续渲染但保持音量为0.
- 利用temporal,小核心,多线程。主核心留给大处理。
移动端空间音频
混响
实时混响:覆盖全地图建筑结构,Matrix Reverb + ReverbTime\Reverb Energy RTPC
卷积混响:表现特征空间,如落日寺,自研卷积混响插件、游戏场景的卷积采样、特定区域触发
卷积混响
就是在真实场景采集到的脉冲信号(IR),能够更真实的还原场景空间特征。
反射
- 通用反射:通过程序实时计算到的反射点、反射参数、播放生成的反射source并控制播放。
- 室外尾音:在反射点播放尾音的样本,并通过RPTC控制尾音大小,可与通用反射叠加。
- 特殊区域尾音:例如峡谷,需要在山谷两头播放尾音。
阻挡(obstacle)
为了节省手机性能,只判断了敌我之间是否有障碍物。损失频段但不损失音量(与视觉提示相配合)。
空间音频的实现
不与基础音频管线耦合。手游音频开发首要目标是项目能运行跑起来,而音频效果的表现优化是在其后面的,因此不能与基础音频管线冲突或者有关联。
开销小并且稳定。在不同机型上都能有稳定的表现。
核心:生成一个与游戏内容实时匹配的AudioScene,在audioscene里面计算模拟最终描述空间音频渲染所需要的数据。
要素Feature
早期反射、后期混响、尾音
现成技术方案:
- 离线
体素:离线写死的方案不适合会实时变动的场景。会过度运算(overdraw)
Probe与体素类似,但优化会好一些。
trigger:场景过大,挂接过于繁杂。 - 实时
几何、波动
早期反射参数需求:反射距离、反射强度、瞬态性
后期混响参数需求:RT60、空间复杂度
尾音参数需求:空间开放度
最终采用方案:
基于icosphere体投影构建一阶声学空间
相较于体素,不会overdraw,计算更为高效。
体投影优势:
每个面彼此独立,可以利用多线程
根据算力的优先级程度可以分配不同朝向的算力分配,也就是面可以细分或者退化。
icosphere优势:
可以分割出top、bottom、middle三个部分。
系统设计
系统优化:
所有计算job化:对于多线程计算任务的抽象。会给每个job分配最低权重,强制让其到小核心运行。
利用temporal;
无效的job剔除;
算法优化:
halton-sequence替代random。
三角形索引。
不规则体积估算。
运行框架:

实现优化
简化曲线
使用ringbuffer实现早期反射:
内存可控:按照最远反射距离30m,48KHZ算≈0.017MB
开销:取决于最大echo数量,手游是三个。
Ringbuffer按需激活:
最多用三个反射的Emitter 表现全部早反:左右中
复杂场景:采用trigger
dobly atmos接入
按照wwise官方说明书进行。
设计考量,将战斗音效接入atmos,其他音乐环境音效走passthrough,避免影响战斗中的声音。
地狱潜兵2游戏混音
声音的优先级设定by HDR(High Dynamic Range)
需要解决的问题-掩蔽
很多声音同时播放,重要的声音听不清楚(掩蔽效应)
解决办法:闪避系统ducking
地狱潜兵中,采用HDR,设置优先级:确定哪种声音更重要?
爆炸声可能比较大,但是附近敌人的声音更重要。——响度≠重要性。优先级设定
首先,将声音进行分类,详细程度可以视情况而定。
优先级映射:什么声音对玩家比较重要,由低到高进行排序。并且,排序低并不代表不重要,而是相对不重要而已。
根据游戏声音分类和优先级排序,进行声音闪避系统设计。
HDR的基础知识
详情参见wwise手册。
- 逻辑音量值-total volume=voice volume +output bus volume +bus volume
- 对于HDR来说, total volume越高,优先级就越高。
- 两个及以上的声音在播放时,优先级高的会对低的进行压低。
- 闪避幅度:等于两个声音total volume 差值。
- 包络:每种声音都指定了HDR包络。利用高优先级的声音对低优先级的声音做闪避处理(就像独立的sidechain)。
哈利波特·魔法觉醒
- 抽卡音效设计
在抽卡中,根据抽卡出的物品材质不同,也会进行细分,而不仅仅只根据卡牌的稀有度。
在抽卡过程中,根据卡片出现的摆放的位置,也会做pan的变化。 - 魔杖/物品展示音效设计
层级:写实层/材质层 + 乐音层 + 特征层 - 节日音频设计
强化节日的音频特色元素。 - 魔法地图声音景观设计
为2D的地图,设计3D的景观。 - puredata+heavy开发的音频混响插件,可以节省音频package的大小。
- IP价值的利用最大化。语音设计中,贴近原著影片声线。
- 创意设计,丰富玩家个性化。兴奋性需求奖励的道具(一开始不抱有期待,但一旦满足则会充满惊喜.)节假日,融入音频设计。中国传统节日,根据现实时间,实现不同声音效果。细节设计上满足玩家的收集欲。时装设定。
- 音频开发从玩家的需求产生,去开发对应的技术。例如,自定义咒语系统;wWISE AUDIO INPUT可以使用外部音频/话筒;从其他音乐平台获取音频串流-音乐电台。
- 音乐电台流程:流媒体平台API - 给出请求清单 - 返回清单获取地址 - …
星球:重启
表现力与性能的均衡与取舍:最大限度地提升单位资源的音频表现力。
环境声交互性:全景声的下混,俯仰角的环境声发生变化。仰角-天空;俯角-地。
- 载具声音的实现
- 动态混音:精细化音频-与玩法是否有关等
需要提前同意音频的标准,优先级,音频播放数量等。
响度设置-不仅仅是音频样本,还包括Wwise中的音频响度。
动态混音可以较早的介入整体音频开发,早期可以粗糙一些,这样可以暴露很多问题 - 分机型测试-安卓与苹果的区别。
-音频程序部分
巅峰极速
车辆运动的声音构成:先进行细分,再部分进行整合。
车辆录制流程:发起录音-预约车辆(私人车主/汽车厂商…)-预约场地-进行录制(赛场跑道录制或者室内马力机录制)。麦克风可承受声压级要大。
轮胎声音的录制。轮胎声音的分类。录制中,赛道漂移音色区别大,定圆漂移稳定的LOOP声。录制过久,轮胎会被磨平,音色会有差异。选择电车(避免排气、引擎等声音的干扰),选择后驱,更好漂移。
轮胎声音后期处理问题:一个样本还是多个样本(性能与表现的取舍);随机样本还是粒子合成(sound seed grain)。轮胎与地面材质。
录音方案的选择:
XY立体声、double MS多通道:近咪芯收音,无相位问题,便于后期处理。
ORTF立体声:接近人耳的听觉感受,用于CG制作。
枪麦录制:补充点声源。音乐与交互音乐
文化与节奏感。